
We present MotionPersona, a novel real-time character controller that allows users to characterize their character by specifying various attributes and projecting them into the generated motions for animating the character. In contrast to existing deep learning-based controllers, which typically produce homogeneous animations tailored to a single, predefined character, MotionPersona accounts for the impact of various character traits on motion as observed in the real world. To achieve this, we develop an autoregressive motion diffusion model conditioned on SMPL-X parameters, textual prompts, and user-defined locomotion control signals. We also curate a comprehensive dataset featuring a wide range of locomotion types and actor traits to enable the training of this characteristic-aware controller. Compared to prior work, MotionPersona can generate motions that faithfully reflect user-specified characteristics (e.g., an elderly person's shuffling gait) while responding in real time to dynamic control inputs. Additionally, we introduce a few-shot characterization technique as a complementary conditioning mechanism, enabling controller customization via short motion clips when language prompts fall short. Through extensive experiments, we demonstrate that MotionPersona outperforms existing methods in characteristics-aware locomotion control, offering superior motion quality and diversity, and adherence to user-specified character traits.
Robust real-time locomotion control
Arbitrary body shape and text input
Example-based characterization
Applicable to various 3D character models
The core of our system is a multi-conditional generative model that synthesizes future motion based on the character's past motion, user-defined control signals, and desired characteristics specified via an SMPL-X shape vector and a textual description. For more details, please refer to our paper.
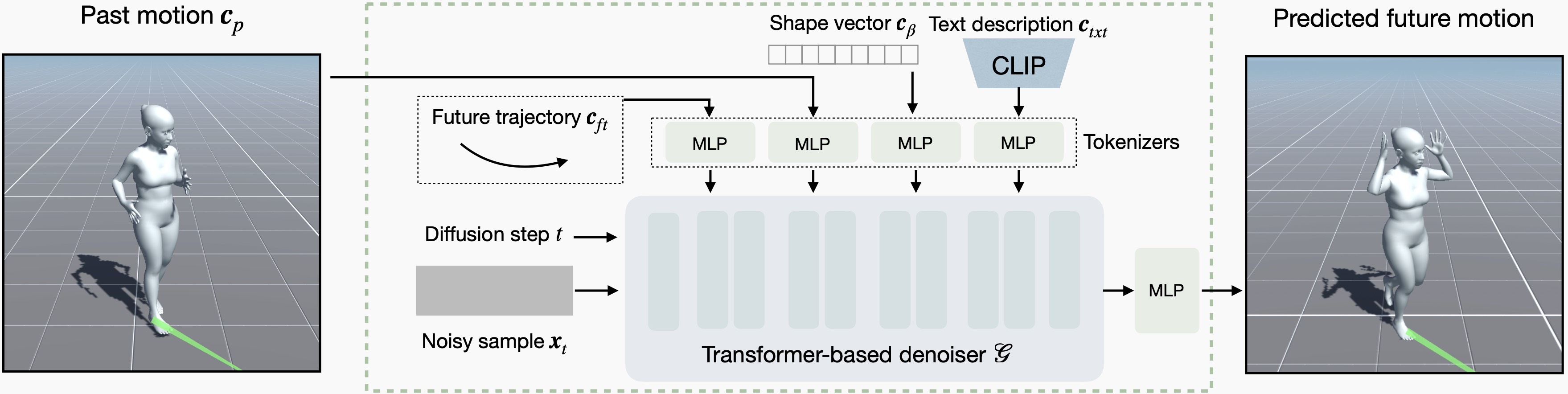
The diffusion model runs in an autoregressive manner, generating future motion conditioned on past motion and multiple conditions.
Existing locomotion datasets are typically collected from a single subject or a small group of subjects, lacking sufficient character-related motion variation. To address this limitation, we have constructed a new dataset called the MotionPersona Dataset. This dataset features diverse locomotion styles and includes human subjects with a wide range of physical and mental states, such as body shape, age, gender, emotion, and personality. To date, our dataset is the most comprehensive locomotion dataset in terms of the character variation, and data scale.
The comparison of the MotionPersona dataset with the existing locomotion datasets

Samples from MotionPersona dataset dataset
With a single, unified controller (3M parameters, 22 MB ONNX model), our system enables real-time control of arbitrary characters. Below, we present video recordings of our real-time demo, showcasing dynamic text input, adjustable body shape parameters, and simultaneous control of multiple characters via batch inference.
Varying Text Input (shape condition is frozen ❄️)
Adjustable body shape parameters (text condition is frozen ❄️)
Multi-character control via batch inference
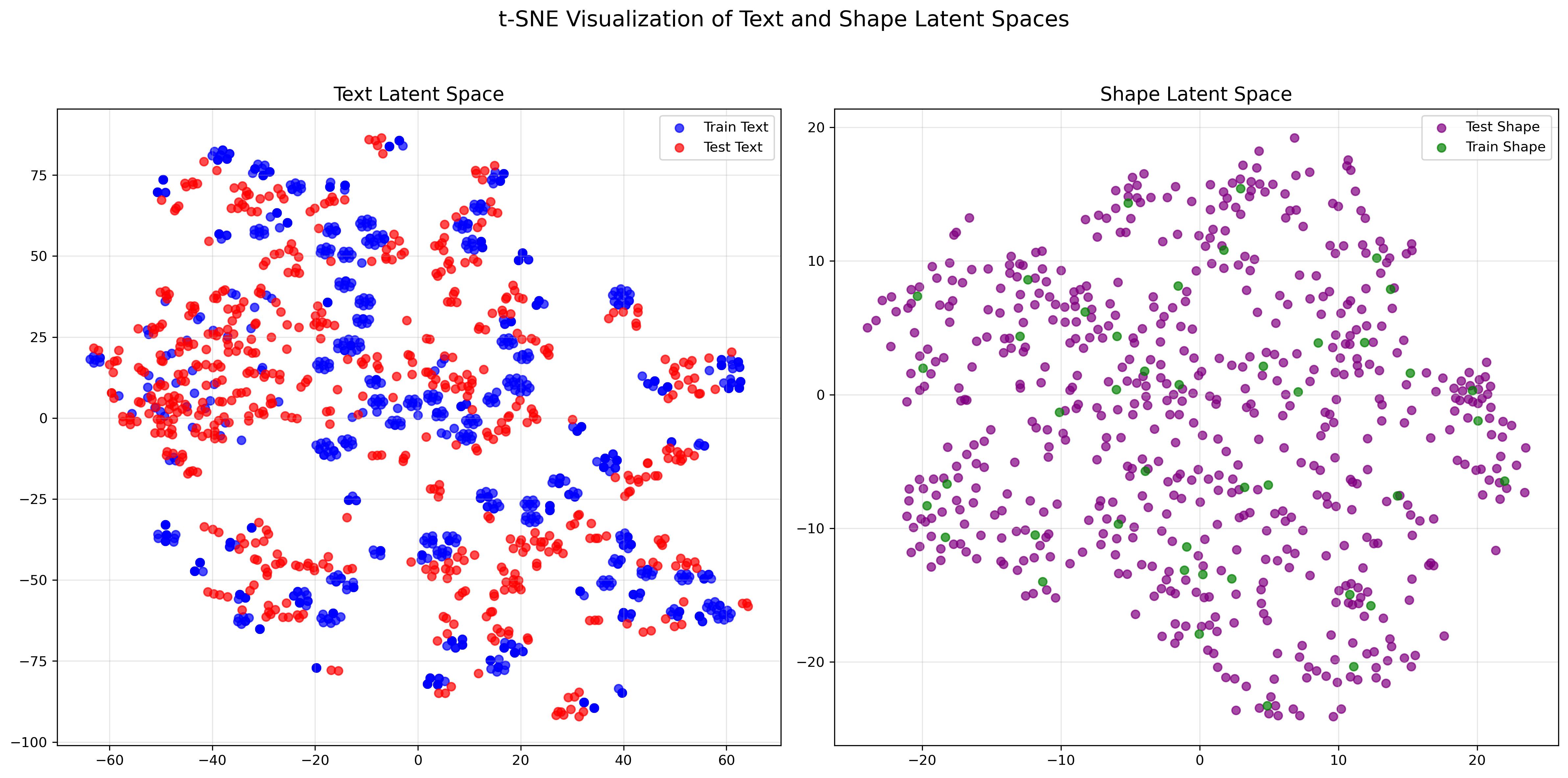
We evaluate the generalization capability of our method on a test set comprising 600 character specifications, generated by large language models and unseen during training. The distribution of both training and test data is shown on the left.
The distribution of the test set and training set
Real-time control of test characters
Our model supports controller characterization with a few short motion clips. As shown below, we use a short motion clip (~10 seconds) captured from multiple performers, and then incrementally implant these unique characters into our pre-trained base controller. This technique enables the generation of motions that lie outside the training distribution and offers a fast, accurate way to produce motions that are difficult to describe using natural language.
Our method can also be adapted to support animating humanoid AIGC characters. Since these characters lack explicit shape parameters, we train a variant of our model that accepts bone lengths as input instead of shape vectors. The text input can be easily annotated by the user.
We conduct ablation studies to evaluate the contribution of different components of our method.
Without in-diffusion blending
Without Shape Augmentation